Intro to LLM in a Non-Technical Perspective
¶Intro to LLM in a Non-Technical Perspective
This is a summary note of the talk presented by Andrej Karpathy at 1hr-talk Intro to Large Language Models.
¶Architecture in Simple Form
We can think of all Large Language Model as two files:
- parameters file (e.g. llama-2-70b 140 GB) why 140GB? 2B (float16) * 70b = 140GB
- run.c (500 lines of C Code)
No network is required in this simplest setting. run.c will use the param file as inputs for text generation.
¶Pre-Training: How Do We Get Parameters File?
Chunk of the internet (~10TB of text) -> 6000GPUs for 12 days, ~$2M ~1e24 FLOPS -> ~140GB file
We can think of the 140 GB file as a compressed ZIP file, we get a lossy compression of the raw data (meaning the raw data cannot be recovered fully from the compressed file).
¶Neural Network: What Do We Get from Training
This neural network will simply predict the next word in the sequence
An Example with context of 5 words:
1 | |
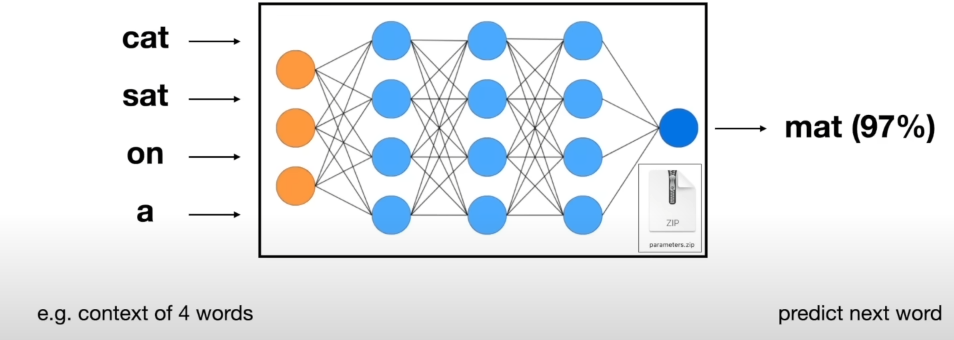
More about the network:
-
The objective of predicting the next word given a prompt is not an easy task.
-
Hallucination: The network make up (parrot) incorrect contents in mimic of some real world content.
¶How Does Network Work?
We do not know how exactly the network works as
- Billon of params are dispersed thru the network
- We only know how to iteratively adjust them to make better prediction
- We don’t really know how the billions of params collaborate to do it.
Think of LLM as the mostly inscrutable artifact in opposite of any engineering discipline.
Now we mostly treat LLM as a empirical artifact in which if we want to use it correctly, sophisticated evaluation is required.
¶Fine-Tuning: Targeting on More Specific Task
To target on a more specific task such as training a AI assistant (like Chat GPT), we do:
- Use the same pre-trained model
- Swap the dataset (question answer dataset)
- Continue training
In contrast to the pre-training (low quality, large quantity), in this stage, we prefer higher quality over quantity.
Empirically, we found that LLM can learn the formatting of the expected answer from the dataset and utilize the knowledge learned from pre-training phase and fine-tuning phase to build up the answer.
¶How to Train Your ChatGPT
- Stage 1: Pre-training (done ~ every year)
- Download ~10TB of text
- Get a cluster of ~6,000 GPUs
- Compress the text into a neural network, pay ~2M$, wait ~12 days
- Obtain the base model
- Stage 2: Fine-tuning (done ~ week)
- Write labeling instructions
- Hire people, collect 100K high quality ideal Q&A dataset
- Fine-tune base model on this data, wait ~1 day.
- Obtain assistant model
- Run a lot of Evaluations
- Deploy
- Monitor, collect misbehaviors, go to step 1.
- Potentilly Stage 3:
- Reinforcement Learning from Human Feedback (RLHF)
- Easier to do comparison than to generating one (select the better generated result from result candidates)

¶LLM Scaling Laws
Performance of LLMs is a smooth, well-bahaved, predictable function of :
- N: the number of parameters in this network
- D: the amount of text we train on
We observed that the trends do not show signs of “topping out”, meaning that we can expect more intelligence “for free” by scaling
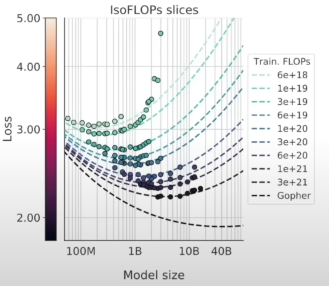
Although we do not care about the next word accuracy in actual practice. in practice, we see that this accuracy is correlated to evaluations we care about.
Algorithmic progress is nice bonus but hard, but this scaling law provides a guaranteed path to success.
¶LLM Uses Tools just like Human Do
LLM can be equipped with tools such as browser, calculators to perform more complex task. Today’s ChatGPT already has some built-in tools it can invoke. some tools already available:
- Browser (Bing search)
- Calculator
- Python Interpreter (e.g. do tasks like plotting)
- DALL-E Image Generation
- Vision
- Speech Communication
This empowers LLM to accomplish sophisticate tasks, only requiring users to give tasks in any natural language.
Also, these tools allow ChatGPT to have multi-modality capabilities.
¶Future Challenges: Two System & Self-improvment
From the book Thinking Fast And Slow
Two types of brain systems are introduced:
- System 1: Quick, Instinctive, Automatic, No Effort, Emotion, Un-conscious (e.g. arithmetic 2+2)
- System 2: Slow, Rational, Complex-Decision, Effortful, conscious (e.g. arithmetic 17 * 24)
For now, current LLM is only capable of System 1, but not System 2.
How can we allow LLM to “think”? prefer accuracy over time
AlphaGo is trained in two steps:
- Learn by imitating human players
- Learn by self-improvement.
What is the step 2 in the domain of LLM? There’s a lack of reward criterion.
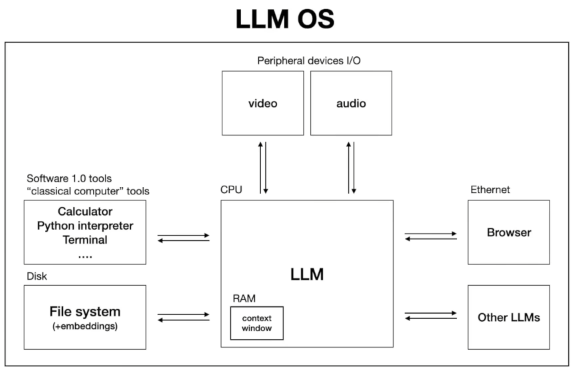
¶A New Perspective of LLM OS
Think LLM as a new emerging kernel process, just like Linux, where it is coordinating with a lot of resources (memory, tools, peripheral devices, ethernet).
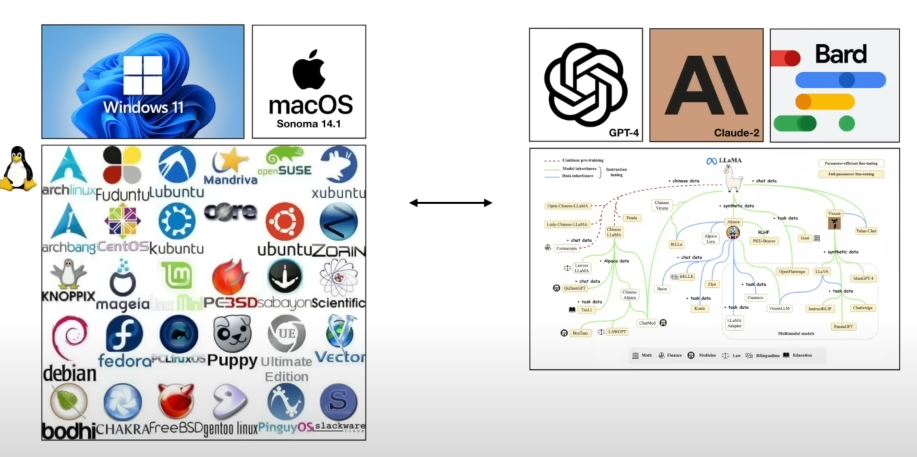
We can also see analogies of proprietary OS and open-source OS with today’s proprietary LLMs and open-source competitors.
¶LLM Security Challenges
Users can disguise the intention and jailbreaks LLM security in a lot of ways.
- Jailbreak attacks by the Grandmother prompt
- Base 64 encoding prompt
- Universal Transferable Suffix
- Noise Pattern
- Prompt Injection
- Data poisoning/ Backdoor attacks
- …
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!